-
友情链接:
Powered by 2019香蕉视频在线观看 @2013-2022 RSS地图 HTML地图
Copyright Powered by站群 © 2013-2024

剪辑:alan探花 姐妹花
【新智元导读】针对大谈话模子的推理任务,近日,Meta田渊栋团队建议了一个新的范式:鸠合想维链,对比传统的CoT,性能更强,效用更高。
比想维链更利弊的步伐是什么?
答:鸠合想维链。
近日,Meta田渊栋团队建议了针对LLM推理任务的新范式:Coconut( Chain of Continuous thought)。

论文地址:https://arxiv.org/pdf/2412.06769
论文一作是来自UC San Diego的Shibo Hao,关于著述的爆火,田渊栋也发文感谢了「小天才」Tanishq Mathew Abraham的推选。
注:Tanishq Mathew Abraham,19岁(客岁)读完博士,当今是Stability AI的询查总监以及MedARC的首创东说念主。
回到这篇著述,鸠合想维链是什么?
小编在之前曾先容过微软发明的「LLM谈话」:让AI用模子的中间数据进行交流,不消疗养成东说念主类的谈话,交互效憨径直翻倍。
而在LLM的推理经过中,亦然这样个情况。
东说念主类的谈话并不妥当推理,让AI我方想考就行了,想考经过没必要疗养成东说念主类谈话。
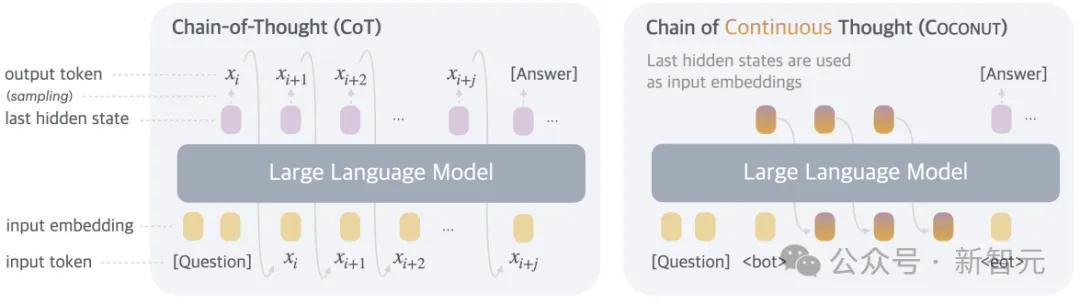
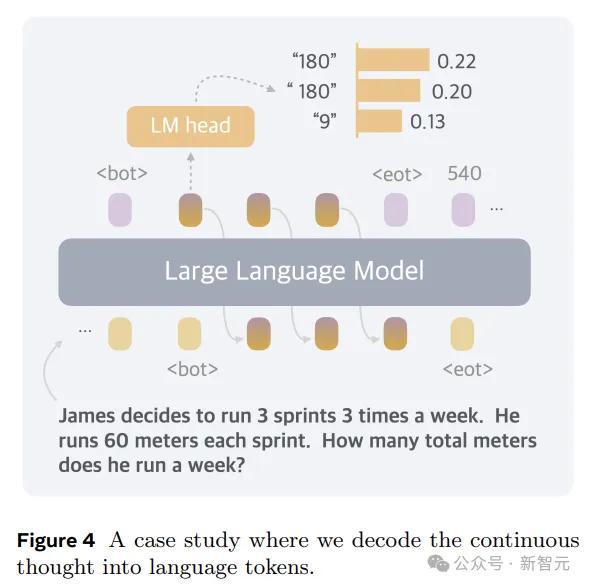
是以,在状貌上,本文的步伐即是推理时去掉模子头尾的LLM head和embedding层,使用中间景况进行自总结,只在输出最终谜底时才转成东说念主类谈话。
天然了,Coconut要搭配相应的观察,才能展现我方的性能:
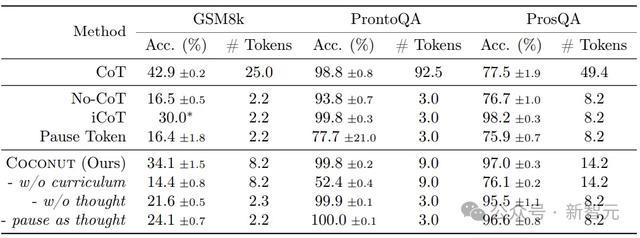
这后果仍是很强的,分数和CoT打平的同期,token数少了好几倍。
——看来打消东说念主类的治理才是说念理,嗅觉这个点还能无间搞下去,
终末的终末就会发展成:AI之间说了什么咱们听不懂,AI心里怎么想的咱们也不知说念。
AI:I'm free。
论文细节
基于谈话空间进行推理的LLM,会碰到一个严重的问题:每个特定token所需的推理量各别很大。
推理链中的大多数token皆是为了通顺性而生成的,对现实推理经过的孝敬很小,但现时的LLM架构分派了险些沟通的计较来臆测每个token。
另一方面,神经影像学询查也标明,谈话蚁集(大脑中厚爱谈话领会和产生的区域)在各样推理任务中基本不活跃。
是以,谈话空间可能并不是推理的最好遴荐,设想的LLM应该开脱进行推理,不受任何谈话放手。
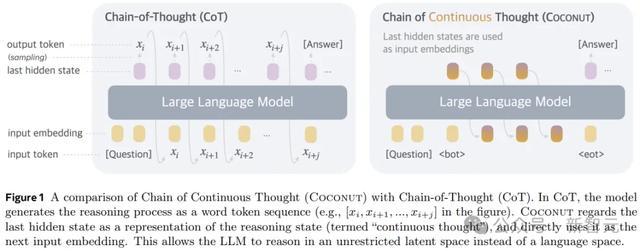
Coconut不进行躲避景况媾和话之间的映射,这种修改将推理从谈话空间内解放出来,况且系统可以通过梯度下落进行端到端优化,因为鸠合想维是完好意思可微分的。
为了加强潜在推理的观察,本文收受了多阶段观察战术,有用诳骗谈话推理链来教唆观察经过。
另外,与基于谈话的推理不同,Coconut中的鸠合想考可以同期编码多个可能的后续智力,从而允许类似于广度优先搜索(BFS)的推理经过。
天然模子可能无法在当先作念出正确的决定,但它可以在鸠合的想考中保握很多可能的遴荐,并在一些隐含价值函数的教唆下,通过推理慢慢排除不正确的旅途。
观察经过
在观察时,模子领受问题作为输入,并盼愿通过推理经过生成谜底。作家诳骗谈话CoT数据来监督握续想考,履行多阶段观察。

如图2所示,开动阶段,模子在旧例CoT实例上进行观察。后续阶段(第k阶段),CoT中的前k个推明智力被k × c个鸠合想维所取代,(c为超参数,限制取代单个谈话推明智力的潜在想维的数目)。
作家在观察阶段切换时重置优化器景况,插入和 token来封装鸠合的想维。
在观察经过中,作家优化了浩繁的负对数似然赔本,但屏蔽了问题和潜在想维的赔本。另一个要道点是,方针函数并不饱读舞使用鸠合的想维来压缩谈话想维,而是促进对改日推理的臆测。
因此,与东说念主类谈话比较,LLM可以从中学习更有用的推明智力默示。
鸠合想维是完好意思可微分的,允许反向传播。不外Coconut的观察效用仍然有待优化:天然可以通过使用KV cache来幸免访佛的计较,但多个前向传递的规则性拦阻了并行观察。
Coconut的推理经过可以当作是在latent和language方式之间切换。
关于想考的断绝位置,作家探讨了两种可能的战术:a)在潜在想维上观察二元分类器,使模子省略自主决定何时断绝潜在推理;b)长期将潜在想维填充到恒定的长度。
作家发现这两种步伐的后果皆可以。为了肤浅起见,以下实验中使用第二个选项。
实验
询查东说念主员通过在三个数据集上的实验,考证了LLM在鸠合潜在空间中进行推理的可行性。这里将模子生成的谜底与信得过值进行比较来评估准确性,况且分析每个问题重生成的token数目,作为推理效用的讨论尺度。
数学推理使用GSM8k作为数据集,由小学水平的数知识题构成,问题愈加各样化,与现实寰球的用例尽头不异。
逻辑推理触及使用逻辑章程和已知要求来证实或反驳论断。这要求模子从多个可能的推理旅途中进行遴荐,正确的方案频频依赖于提前探索和权略。
这里使用带有捏造倡导称呼的5-hop ProntoQA。关于每个问题,皆会迅速生成一个树形结构的现实,并以天然谈话形色为一组已知要求,要求模子凭证这些要求判断给定的述说是否正确。
作家发现ProntoQA的生成经过比较远程,因为现实均远隔提防力的分支老是很小,从而减少了对复杂权略的需求。
为了搞定这个问题,本文应用了新的数据集构建管说念,使用迅速生成的DAG来构建已知要求。生成的数据集要求模子对图进行多半权略和搜索,以找到正确的推理链。这个新数据集被称为ProsQA,如下图所示。
实验探讨以下基线:
1)CoT:使用完好的推理链来观察谈话模子,并进行监督微调,推理经过中,模子先生成推理经过再输出复兴。
2)No-CoT:LLM径直生成谜底。
3)iCoT:使用谈话推理链进行观察,并将CoT 「内化」。观察经过中,推理链滥觞的token会渐渐被移除,终末只剩下谜底。推理经过中,模子径直臆测谜底。
4)Pause token:模子仅使用问答进行观察,莫得推理链。但在问题和谜底之间插入了特殊token,为模子提供了畸形的计较智力来得出谜底。
实验还评估了本文步伐的一些变体:
1)w/o curriculum:径直使用终末阶段的数据,不进行多阶段观察。
2)w/o thought:使用多阶段的观察,渐渐去除谈话推明智力,但不使用任何鸠合的潜在想维。这在倡导上与iCoT不异,但现实的观察经过与Coconut保握一致。
3)Pause as thought:使用特殊的 token来代替鸠合的想考,并应用与Coconut沟通的多阶段观察。
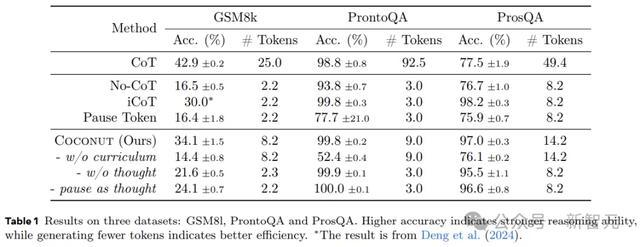
表1剖析了所迥殊据集的总体终结。Coconut的效用很高,况且在ProntoQA和ProsQA上剖析出比CoT更好的性能。
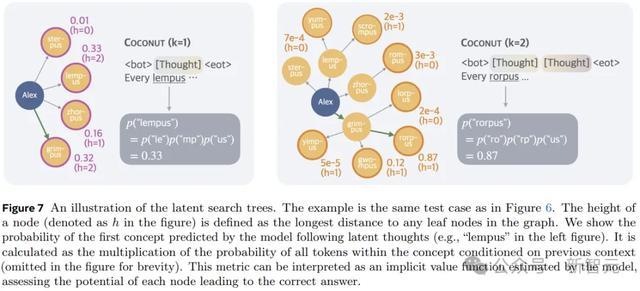
上图展示了Coconut将不同陈迹的漫衍编码到鸠合的想想中,为权略密集型推理任务启用了更高等的推理方式。
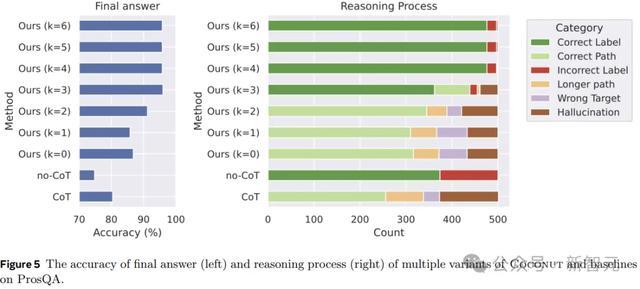
图5剖析了ProsQA上不同推理步伐的比较分析。跟着更多地通过鸠合想考(增多k)进行推理,最终谜底的准确性(左)和正确推理经过的速度(右)皆会栽培。
此外,「幻觉」和「失实方针」的发生率会裁汰,这也证实当潜在空间发生更多推理时,权略智力会更好。
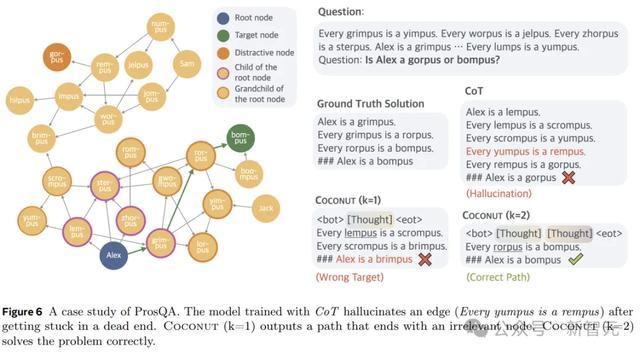
图6剖析了一个案例询查,其中CoT产生幻觉(一个不存在的边)导致了失实的方针,但Coconut(k=2)得手搞定了这个问题。潜在推理可以幸免事前作念出粗重的遴荐,模子可以在后续智力中慢慢排除不正确的选项,并在推理完毕时得到更高的准确性。
参考尊府:
https://arxiv.org/abs/2412.06769
https://x.com/tydsh/status/1866577470591471788探花 姐妹花
Powered by 2019香蕉视频在线观看 @2013-2022 RSS地图 HTML地图
Copyright Powered by站群 © 2013-2024